C++20: A coroutine based stream parser
In this post, I like to show you how C++20's coroutines can help you when writing a stream parser. This is based on a protocol Andrew Tanenbaum describes in his book Computer Networks. The protocol consists of a Start Of Frame (SOF) and ESC to escape characters like SOF. Hence, ESC + SOF mark the start of a frame as well as the end. In today's exercise, we will parse the string Hello World (yes, without the comma, sorry). For simplicity, I use strings and not bytes. The following stream is what we are going to process:
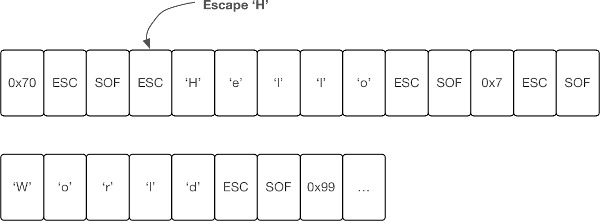
The classic way
Before C++20, we could have quickly written a function ProcessNextByte, which deals with tokenizing the stream. It looks for the ESC + SOF for the start of a frame and calls the callback frameCompleted once a frame is complete. Error cases are not treated for simplicity here. They are silently discarded. Here is a version of ProcessNextByte:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
There are other ways to implement this, such as, using a class and getting rid of the static variables. However, this is essentially what we like here. This is not really a job for a class. Even with a class tracking the state and quickly seeing where we are, remains complicated. Another way, of course, is to bring in the big guns and use some kind of state pattern using virtual methods. I once had the pleasure of working with such a beast. It turned out that it was very hard to see the control flow, and in the end, all calls ended up in one single class, which contained the actual logic.
However, one upside of using a class would be that we can have multiple objects parsing multiple streams. With the given ProcessNextByte we can only parse exactly one stream.
Coroutines applied
Here is the same logic, this time as coroutine:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
There are various great things. First, Parse is not a template, as ProcessNextByte was. By looking at the function's body the states are much clearer to see. We have two infinite-loops (which is a sad thing on some embedded systems as infinite-loops are usually avoided) where the outer is really infinite and the inner runs as long as the frame is incomplete. We can see that this code first looks for ESC and then for SOF A. If ESC is found, but the next byte is not SOF, the search for ESC starts over. The logic above was way more complicated and harder to see through.
Once ESC followed by SOF is found, the inner loop starts B. It adds all received bytes to the local variable frame. But before that, Parse checks whether we are looking at an escape sequence C. If so, the escape character is removed and replaced by the unescaped version. In our case, this is necessary for ESC as its value is 'H'. As there are no other characters we need to escape, for now, we only check whether the byte following ESC is either SOF or ESC. Both are valid. Any other byte is a processing error, which we silently discard by throwing away the current frame and starting over from the beginning.
I claim that this code is fairly straightforward to read, without knowing what co_await and co_yield do. I'm sorry about the co_, but coroutines were too late for the party, and keywords like await or yield were already used in code-bases, hence the prefix.
We can also see something new. Parse returns FSM, my name for this coroutine type.
While I like the version I showed you above, there is something I like not so much. We need to write a huge amount of boilerplate code to make all the coroutine elements come alive. Sadly C++20 does not ship with a coroutine library. All in the coroutine header are very low-level constructs, the building blocks required for a great coroutine library. Lewiss Baker maintains cppcoro in GitHub and is the author of various proposals for a great coroutines library in C++23. If you are looking for a promising shortcut that has a good chance of ending up in the STL cppcoro is the choice.
BYOC (Bring your own coroutine)
Let's look at how we can implement the missing pieces without any other library, only the STL.
The type FSM
First, what is FSM? It is a using alias to async_generator<std::string, byte>:
1 | |
async_generator is another type we have to write, one way or the other, to satisfy the coroutine interface. This type consists of a special type, or in this case, a using alias promise_type. This is a name the compiler looks for to determine whether async_generator is a valid coroutine type. Precisely with this spelling! Below we see the implementation of async_generator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
With the call operator, we get access to the value from inside the coroutine. This is the receiving end of something that can be seen as a pipe. The pipe is filled on the other end, inside the coroutine, by co_yield.
We can put data into the pipe with SendSignal. This is received inside the coroutine by a co_await.
Because async_generator holds a communication channel with our coroutine, we only allow this type to be moveable but not copyable. An instance of this type is created for us by the compiler when instantiating an object of type promise_type. This is why I chose to make the constructor of async_generator private and say that promise_type is a friend. This is just to prevent misuse or false assumptions.
PromiseTypeHandle is a handle to the current coroutine. With it we can transfer data between normal and coroutine code (e.g. co_yield and co_await).
Next up is the promise_type. The using alias is directing to promise_type_base, which is composed by T, async_generator, awaitable_promise_type_base<U>. So two more new types.
The promise_type_base
First, the reason for the suffix _base is that the entire example uses two generators. One for the parsing logic we are looking at and another one for simulating a data stream. Here is the implementation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
This generator satisfies the co_yield interface of a coroutine. A very rough view is that the call co_yield is replaced by the compiler calling yield_value. So promise_type_base serves as a container for the value coming from the coroutine into our normal code. All the other methods are just to satisfy the coroutine interface. As we can see, coroutines are highly customizable, but that is a different story.
We can also see that promise_type_base derives from the third parameter passed to it. In our case, this is awaitable_promise_type_base<U>. This is a variadic argument, simply to allow creating a promise_type_base object without a base class.
The awaitable_promise_type_base
Next, we need to write the glue code for co_await, which waits for the next byte. This is the part of awaitable_promise_type_base, creating a so called Awaitable-type. Below you see an implementation:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
With these pieces, we have the FSM coroutine type and can use Parse. The following figure shows which element in our code interacts with which part of the async_generator:

Summary
I hope I could demonstrate that coroutines are a great tool when it comes to implementing parsers. The boiler-plate code aside, they are easy to write and highly readable. You can find the complete version of this example here.
Until we have C++23 and hopefully much better coroutines support in the STL, we either have to write code as above or use cppcoro.
As always, I hope you learned something from this post. Feel free to reach out to me on Twitter for feedback.
Andreas