C++20 Modules: The possible speedup
C++20's modules are one feature of the big four, supposed to influence how we write C++ code in a huge way. One expectation I hear nearly all the time is the improvement of compilation times. In this post, I like to shed some light on this part of modules.
The include system
First, let's recap how the #include system works and what the drawbacks are there. Consider the following figure.
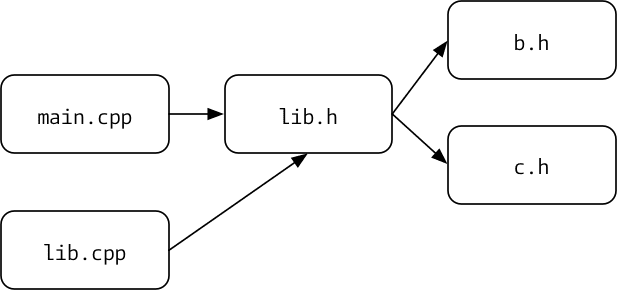
This models a typical C++ program. We have our main.cpp, which includes a single header file lib.h. Yet, this header file includes two other headers b.h and c.h. Of course, the nesting can go on and on.
When we start to compile main.cpp, the preprocessor is the first process that runs. Its job is to process all the #include statements (and the #define, but we ignore them for now). The process there is to look for #include then lookup the file on the file system, open and read it and copy the content into the file which triggered the #include. In our example, the contents of lib.h are copied into main.cpp. I think it is not important how exactly the compiler does implement the next order of includes. We can simply say that this process continues for main.cpp until in a run no more #include are spotted. Thus ending up with all the contents of lib.h, b.h, and c.h are in main.cpp.
Should you never have heard or seen this, or you just forgot, have a look at this code in Compiler Explorer.
1 2 3 4 5 6 | |
All I did was adding -E to the compiler options. This gives a view of the source code after the preprocessor did run. The initial six lines of source code become 34.780 lines of code ready for the compiler to be compiled after I included only one header!
Now, assume that we link main.cpp to another object file (or library) lib.o. This object file is created by lib.cpp, which includes lib.h as well.
We look at a scenario where lib.h is included two times, as well as b.h and c.h. For each of these files, the compiler needs
- to look the file's location up in its search path,
- open the file,
- read the file,
- copy its contents into the designated including file. In our example the contents of
lib.hintomain.cppand so forth.
Should one of these files be stored on a slow disk, maybe in the cloud or one of these ancient disk drives, then such a read takes a significant amount of time of the compilation process. The worst is, even if we change only main.cpp and recompile it. All the included headers are once again copied into main.cpp despite the fact that they haven't changed.
What also increased due to the simple copy and paste approach is the time it takes to compile main.cpp after the preprocessor did already run. Why? Because main.cpp contains more code now. To be precise, all the code of lib.h, b.h, and c.h. Yes, if we are careful, then we did offload a lot of the actual implementation parts of these headers into the cpp file of our library, but at least the definitions need to be there. All these definitions need to be parsed. If there is code, it needs to be compiled in addition to what initially is in main.cpp. Especially this repetitive read of the entire include hierarchy is costly in terms of time.
What changes with modules
Please note that in a full module world there are no .h files anymore. The following section says .h to keep the mental model. We would have a module interface unit instead and possibly module partitions in a module world.
If we look only at the compilation speed, then modules do, more or less, the same thing as some of you may already know as pre-compiled headers. Instead of reading all header files all the time, the compiler reads them once and creates a pre-compiled module from it. This way, the compiler needs to parse all the files only once, and it can store the parsed information in an efficient format for later use. You can compare it to storing the AST of the files in binary form, but compilers are free on the format and information here. This resulting file, say lib.pcm (for the pre-compiled module), is then read all the time we say import "lib"; in our code. This lib.pcm file is now possibly bigger than lib.h, but there is no need to look for the next include hierarchy. Another plus is that file systems are usually much faster in reading a single big file instead of multiple smaller onces.
This lib.pcm needs to be recompiled each time the contents of either lib.h, b.h, or c.h are changed.
Potential speed-up summary
To summarize, where can you expect a speed-up from:
- Each
importreads only one file regardless of how many files are included or imported internally on the header/module. - This content is stored in a well-to-handle format for the compiler. Directly usable, so no potential undefined symbols etc.
- All defines are already replaced as well, so the preprocessor does not need to be invoked for a
.pcmfile after it was created. This drops starting one process which itself costs time. - Reading one larger file instead of finding and reading multiple smaller files can give another speed-up.
- The compilation of the cpp source files is possibly faster as the content of the include files is not copied into the source file.
What else?
Please note, this is only the potential speed-up part of modules. I think they excel even more when it comes to the new ways of exposing API's or better hiding implementation details. I will talk about this in my next post.
Andreas